Weights & Biases Weave - Tracing and Evaluation
What is W&B Weave?
Weights and Biases (W&B) Weave is a framework for tracking, experimenting with, evaluating, deploying, and improving LLM-based applications. Designed for flexibility and scalability, Weave supports every stage of your LLM application development workflow.
W&B Weave's integration with LiteLLM enables you to trace, version control and debug your LLM applications. It enables you to easily evaluate your AI systems with the flexibility of LiteLLM.
Get started with just 2 lines of code and track your LiteLLM calls with W&B Weave. Learn more about W&B Weave here.
Quick Start
Install W&B Weave
pip install weave
Use just 2 lines of code, to instantly log your responses across all providers with Weave.
import weave
weave_client = weave.init("my-llm-application")
You will be asked to set your W&B API key for authentication. Get your free API key here.
Once done, you can use LiteLLM as usual.
import litellm
import os
# Set your LLM provider's API key
os.environ["OPENAI_API_KEY"] = ""
# Call LiteLLM with the model you want to use
messages = [
{"role": "user", "content": "What is the meaning of life?"}
]
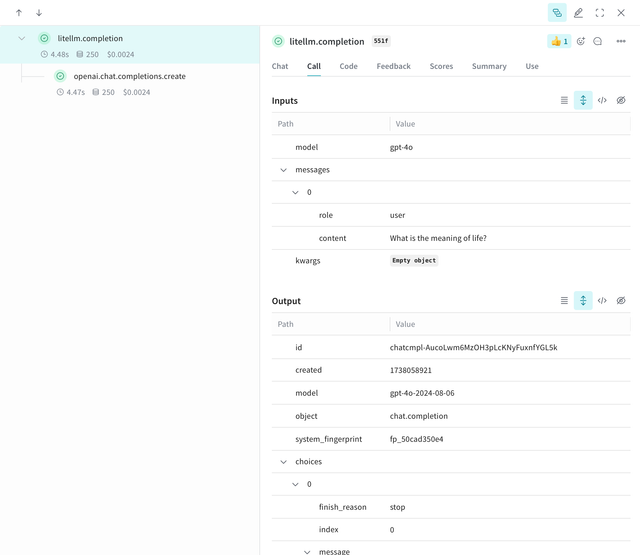
response = litellm.completion(model="gpt-4o", messages=messages)
print(response)
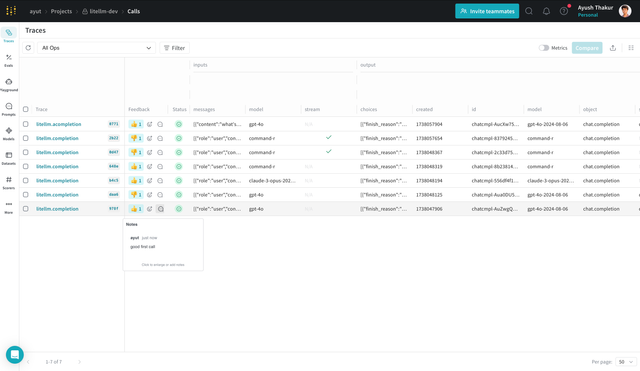
You will get a Weave URL in the stdout. Open it up to see the trace, cost, token usage, and more!
Building a simple LLM application
Now let's use LiteLLM and W&B Weave to build a simple LLM application to translate text from source language to target language.
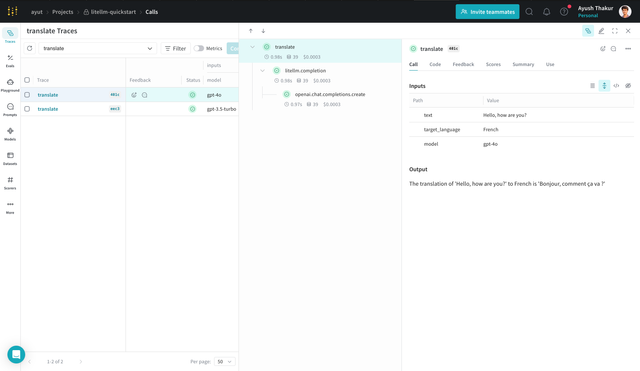
The function translate takes in a text and target language, and returns the translated text using the model of your choice. Note that the translate function is decorated with weave.op(). This is how W&B Weave knows that this function is a part of your application and will be traced when called along with the inputs to the function and the output(s) from the function.
Since the underlying LiteLLM calls are automatically traced, you can see a nested trace of the LiteLLM call(s) made with details like the model, cost, token usage, etc.
@weave.op()
def translate(text: str, target_language: str, model: str) -> str:
response = litellm.completion(
model=model,
messages=[
{"role": "user", "content": f"Translate '{text}' to {target_language}"}
],
)
return response.choices[0].message.content
print(translate("Hello, how are you?", "French", "gpt-4o"))
Building an evaluation pipeline
LiteLLM is powerful for building evaluation pipelines because of the flexibility it provides. Together with W&B Weave, building such pipelines is super easy.
Below we are building an evaluation pipeline to evaluate LLM's ability to solve maths problems. We first need an evaluation dataset.
samples = [
{"question": "What is the sum of 45 and 67?", "answer": "112"},
{"question": "If a triangle has sides 3 cm, 4 cm, and 5 cm, what is its area?", "answer": "6 square cm"},
{"question": "What is the derivative of x^2 + 3x with respect to x?", "answer": "2x + 3"},
{"question": "What is the result of 12 multiplied by 8?", "answer": "96"},
{"question": "What is the value of 10! (10 factorial)?", "answer": "3628800"}
]
Next up we write a simple function that can take in a sample question and return the solution to the problem. We will write this function as a method (predict) of our SimpleMathsSolver class which is inheriting from the weave.Model class. This allows us to easily track the attributes (hyperparameters) of our model.
class SimpleMathsSolver(weave.Model):
model_name: str
temperature: float
@weave.op()
def predict(self, question: str) -> str:
response = litellm.completion(
model=self.model_name,
messages=[
{
"role": "system",
"content": "You are given maths problems. Think step by step to solve it. Only return the exact answer without any explanation in \\boxed{}"
},
{
"role": "user",
"content": f"{question}"
}
],
)
return response.choices[0].message.content
maths_solver = SimpleMathsSolver(
model_name="gpt-4o",
temperature=0.0,
)
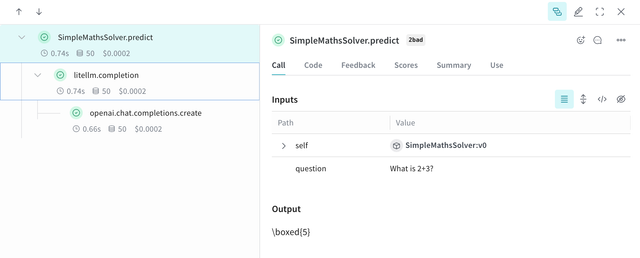
print(maths_solver.predict("What is 2+3?"))
Now what we have the dataset and the model, let's define a simple exact match evaluation metric and setup our evaluation pipeline using weave.Evaluation.
@weave.op()
def exact_match(answer: str, output: str):
pattern = r"\\boxed\{(.+?)\}"
match = re.search(pattern, output)
if match:
extracted_value = match.group(1)
is_correct = extracted_value == answer
return is_correct
else:
return None
evaluation_pipeline = weave.Evaluation(
dataset=samples, scorers=[exact_match]
)
asyncio.run(evaluation_pipeline.evaluate(maths_solver))
The evaluation page will show as below. Here you can see the overall score as well as the score for each sample. This is a powerful way to debug the limitations of your LLM application while keeping track of everything that matters in a sane way.
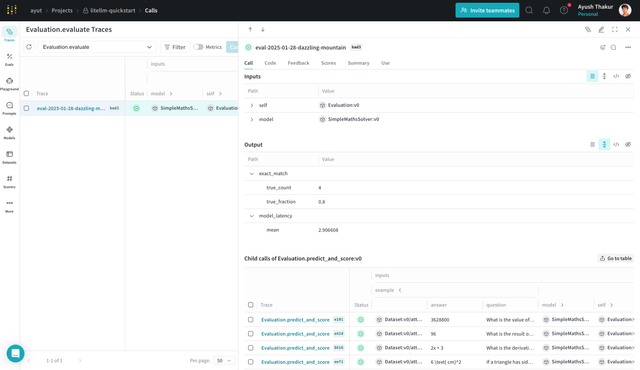
Now say you want to compare the performance of your current model with a different model using the comparison feature in the UI. LiteLLM's flexibility allows you to do this easily and W&B Weave evaluation pipeline will help you do this in a structured way.
new_maths_solver = SimpleMathsSolver(
model_name="gpt-3.5-turbo",
temperature=0.0,
)
asyncio.run(evaluation_pipeline.evaluate(new_maths_solver))
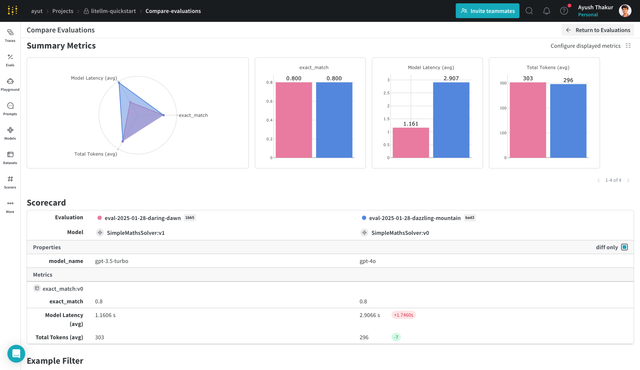
Support
- For advanced usage of Weave, visit the Weave documentation.
- For any question or issue with this integration, please submit an issue on our Github repository!